

By the beginning of March, I had had about six months experience with ChatGPT. If I were grading the experience, I would have given it a C+. When I said “grading the experience,” I was including myself in the assessment. But I wasn’t a fan of the interface—large font size and lots of white space and not modifiable— which, when combined with the often excessive responses, always made reading and reviewing the content seem unwieldy and a little disorienting. I also found many of our interactions to be full of superfluous suggestions. I felt I was spending too much time trying to weed through the abundance of options and information to be efficient.
I might have tried a little longer to see if I could learn to produce better responses but then came the breaking news on February 27 that the Pentagon was canceling its contract with the AI company Anthropic. Anthropic was refusing the government’s demand to lift previously agreed upon safeguards on its Claude AI model that would keep it from being used in “fully autonomous weapons” and for “mass domestic surveillance.” Secretary Hegseth took the drastic step of declaring Anthropic a “supply chain risk to national security,” effectively blacklisting it for use by any federal government agencies or contractors, a move previously only applied to foreign adversaries. Three days later OpenAI, the maker of ChatGPT, signed the contract with the Department of War.
Anthropic immediately filed two lawsuits. According to CNN, nearly 150 retired federal and state judges—appointed by both Republicans and Democrats—have filed an amicus brief supporting Anthropic, joining a growing list that includes industry organizations, former national security officials, and Microsoft. Meanwhile, the Claude AI app began riding the public backlash to greater public awareness and popularity. It surpassed ChatGPT for the first time on the iPhone App Store and the company reported new accounts exceeding one million per day.
I was one of them.
I began by uploading much of my Substack content to “brief” Claude quickly and thoroughly on my work history. I uploaded a summary of what I had started in ChatGPT on a new memoir vignette. The first thing we worked on was getting the workspace organized in a way that works for me and for Claude’s memory. I learned a couple of fascinating things about how the platform works in the process.
The first screenshot shows Claude’s Projects screen. I created three projects — one for each of the three sections of my Substack (My 2 Cents, The Memoir Project, and AI Field Notes). The fourth is a built-in example project Anthropic provides called “How to Use Claude.” Think of each project as a dedicated workspace. When I start a new post or memoir vignette, I open the relevant project and start a new chat inside it. All the chats related to, say, the memoir live together in The Memoir Project. All the chats related to political and cultural commentary live in My 2 Cents. The organization mirrors the publication itself.
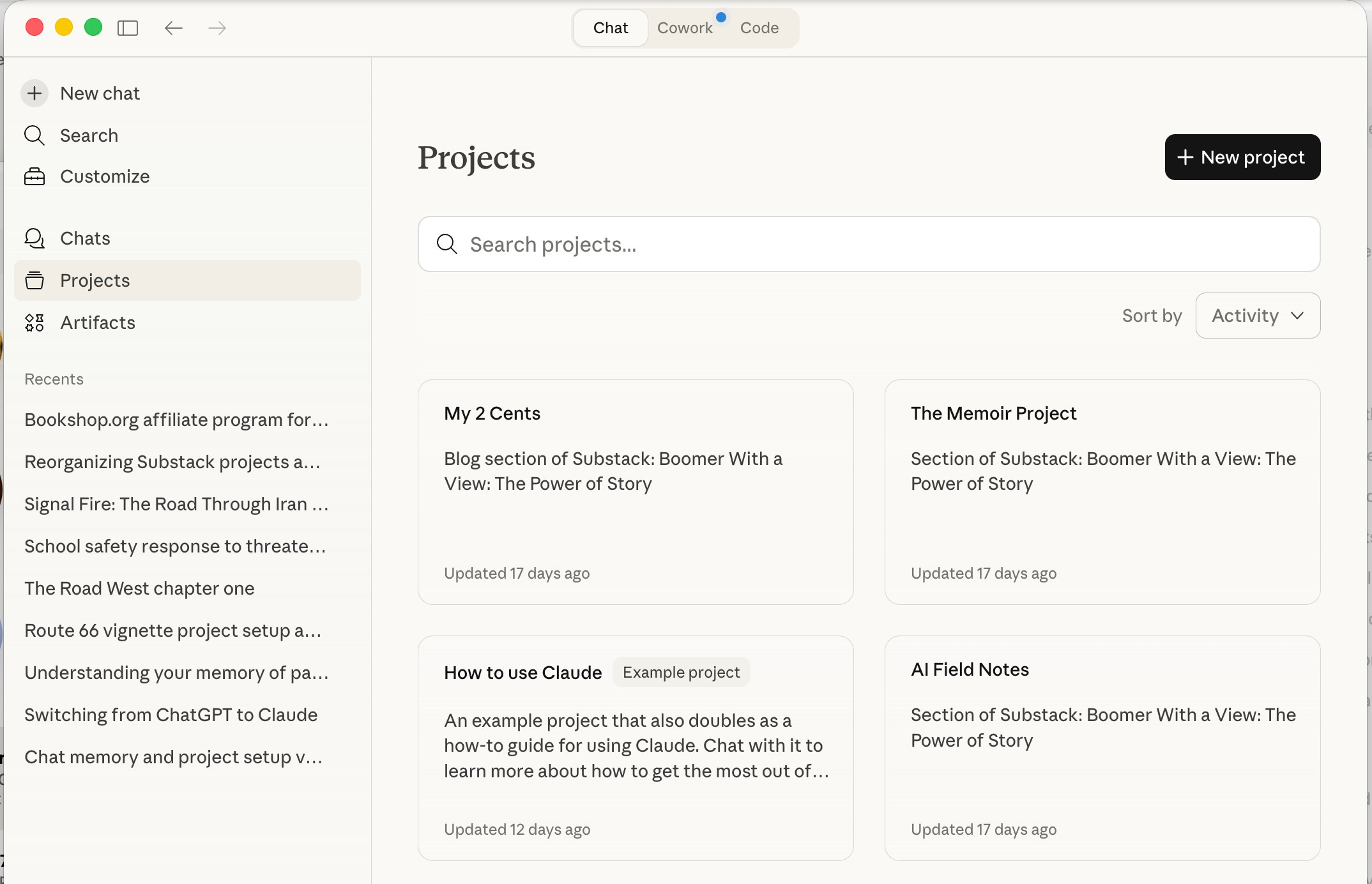
The second screenshot shows what’s inside The Memoir Project. On the left, the individual chats: The Road West chapter one, Route 66 vignette project setup, Chat memory and project setup verification. Each chat is its own working session — research for a particular vignette, a drafting session, a planning conversation. On the right side of the screen is where things get interesting.
That right panel has three sections: Memory, Instructions, and Files. The Files section is visible in the screenshot — four documents currently uploaded to the project: the Project Knowledge document, a transcript of my earlier ChatGPT sessions on the Route 66 vignette, my Route 66 research notes, and the cloakroom draft. These files are available to Claude across every chat in the project.
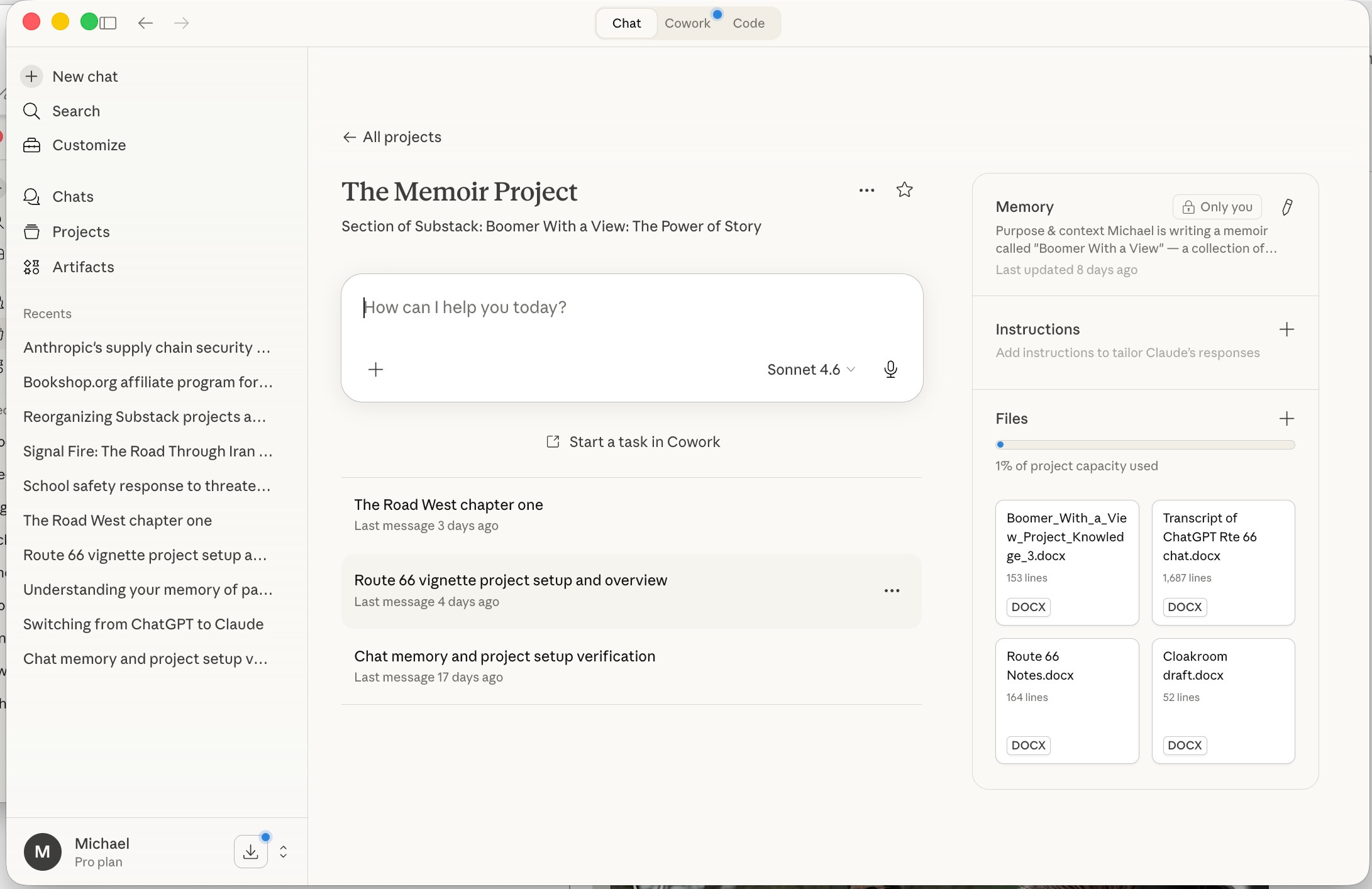
Which brings me to memory — and this is the part that took me a while to understand correctly.
Claude does not remember our previous conversations the way a human colleague would. When I start a new chat, I’m not picking up where we left off. I’m starting fresh with an AI that has no recollection of anything we’ve done together. What it does have — if I’ve set things up properly — is the Project Knowledge document, which I upload to the Files panel and which Claude reads at the start of every chat. That document carries the continuity. It tells Claude who I am, what the project is, what decisions have been made, what the voice and method are, where each vignette stands. It’s the institutional memory of the project, maintained by me, available to Claude on demand.
I asked Claude directly about this — about whether it “experiences” time passing between our sessions. I thought it might do something like accessing timestamps embedded in the chats and be programmed to simulate human memory. The answer was clarifying:
“No, I don’t experience time passing between sessions. When a conversation ends I have no awareness of duration — an hour and a year feel identical, which is to say neither feels like anything at all. Each new chat I begin without any sense of ‘it’s been a while.’ What I do have is whatever context you bring back in — the Project Knowledge document, a summary, an uploaded file. That’s the only continuity available to me. It’s genuinely different from human memory, and worth noting accurately in the Field Notes when you get there.”
Worth noting accurately — that’s the standard I’m trying to hold myself to in these Field Notes. Claude doesn’t remember me. But if I do my job with the Project Knowledge document, it knows enough to do its job. That’s a workable arrangement. It’s just not the same as memory, and it shouldn’t be described as if it were.
As a postscript, and in the spirit of noting accurately, I asked Claude to bail me out in this Note after I flailed around a while trying to explain what the screenshots illustrated. Then I realized I had a resident expert available with nothing else to do. So he wrote most of the last half, with some light editing by me. Which is, itself, a pretty good example of how this works.
Ha! I had a feeling you weren't gonna waste any time switching to Claude. I'm gonna import my ChatGPT "memories" into Claude over spring break. :)